Introdução
Esse cenário atual de IA, LLMs e mais um monte de coisas (um ‘boom’ de assuntos que convergem para o mesmo caminho) me faz refletir muito sobre formas de otimização do que já possuímos e, aos poucos, conseguirmos escalar nossas soluções. Pensando nisso, falar sobre RAG é um ponto e um assunto interessante. Dito por outros autores, LLMs têm um custo computacional alto no quesito implantação e funcionamento. Além disso, aprendem com dados antigos. Como melhorar isso? No caso, como melhorar o aprendizado de algo que sabe apenas do passado?
Posto de uma forma um pouco mais coerente, os Grandes Modelos de Linguagem (LLMs) são, de forma muito simplista, grandes modelos probabilísticos que têm como base de aprendizado uma massa de dados obtida em um determinado momento. Este momento é o passado. Ou seja, esses modelos são treinados com dados antigos e, hoje, por exemplo, se eu perguntasse a um modelo treinado em 2020 “qual é a minha idade?”, ele responderia “Você tem X anos”. No caso, o modelo foi treinado para saber apenas sobre mim, porém com os dados que ele tinha naquele momento. Certo? Daí, todas as perguntas que eu fizer a ele sobre o Jackson daquele momento serão respostas que contêm dados antigos. Agora, a pergunta é: como corrigir isso?
Antes de falar sobre como resolver isso, notem que, no exemplo anterior, caso eu perguntasse algo sobre o atual presidente da república e sua idade, o modelo não teria dados sobre isso. Essa é outra problemática sobre LLMs. A base de dados com a qual treinamos nosso modelo, de maneira bem generalista, o fará especialista em um determinado contexto, não em todos. Ele não saberá sobre as outras pessoas e suas idades também.
Voltando à pergunta “como corrigir isso?”, temos, hodiernamente, inúmeras possibilidades, algumas mais factíveis e outras nem tanto. Das que vejo como viáveis, temos o RAG. Extendendo sua sigla, é o Processo de Recuperação Aumentada, do inglês Retrieval-Augmented Generation. Traduzo como “processo” por conta do contexto em que se aplica e de sua funcionalidade, mas, adiante, explico.
O que é RAG?
RAG é um processo que foi introduzido em meados de 2020 e início de 2021 por um time de pesquisadores que incluía membros do Facebook AI Research, da University College London e da New York University. O artigo, com título Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, falava sobre uma abordagem inovadora chamada de mesmo nome e que combinaria modelos de recuperação de informações com modelos generativos (os nossos LLMs) para melhorar o desempenho em tarefas de Processamento de Linguagem Natural (NLP) que exigem conhecimento externo, como questões e respostas, resumo de texto e tradução.
O foco estaria em tarefas que são “conhecimento-intensivas”, ou seja, aquelas que não podem ser resolvidas apenas com o que foi aprendido durante o treinamento do modelo, mas que precisam de informações adicionais provenientes de fontes externas.
Dito isso, de forma conceitual, o RAG seria, portanto, o processo de recuperação de informações externas à especialidade da LLM, de modo que, ao inserir essas informações no processo de inferência do modelo, ele não precise ser retreinado, possuindo, assim, contextos diversos e independentes do seu contexto atual.
Estrutura Clássica
No mesmo artigo, os autores propuseram uma estrutura, um fluxo para o que seria RAG naquele momento. Na imagem abaixo, retirada desse artigo, podemos observar a estrutura proposta pelos autores.
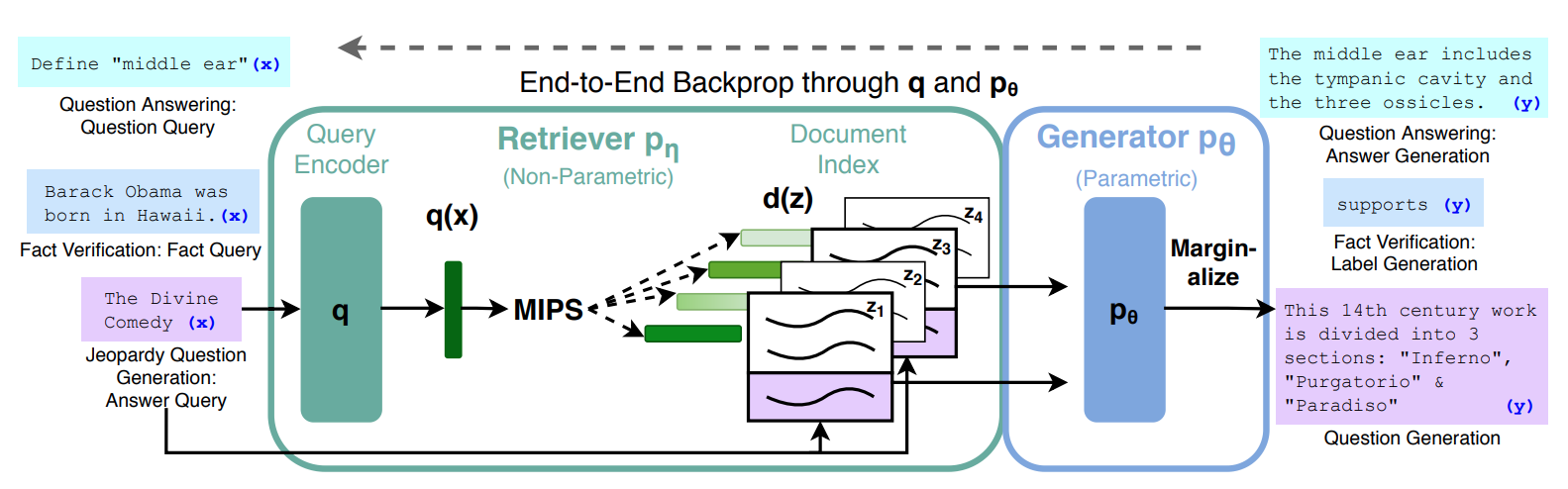
No diagrama, eles combinam um recuperador pré-treinado (Codificador de Consultas + Índice de Documentos) com um modelo seq2seq pré-treinado (Gerador) e ajustam todo o processo de forma end-to-end. Para a consulta x, usam a Pesquisa de Máximo Produto Interno (MIPS) para encontrar os documentos mais relevantes zi. Para a previsão final y, tratam z como uma variável latente e fazem a marginalização sobre as previsões do seq2seq, dadas diferentes consultas.
Eu sei que complicou. Mas, vamos descomplicar agora. Na imagem a seguir, temos outro diagrama que nos ajudará a entender esse fluxo do RAG no processo de geração de respostas pelo LLM.
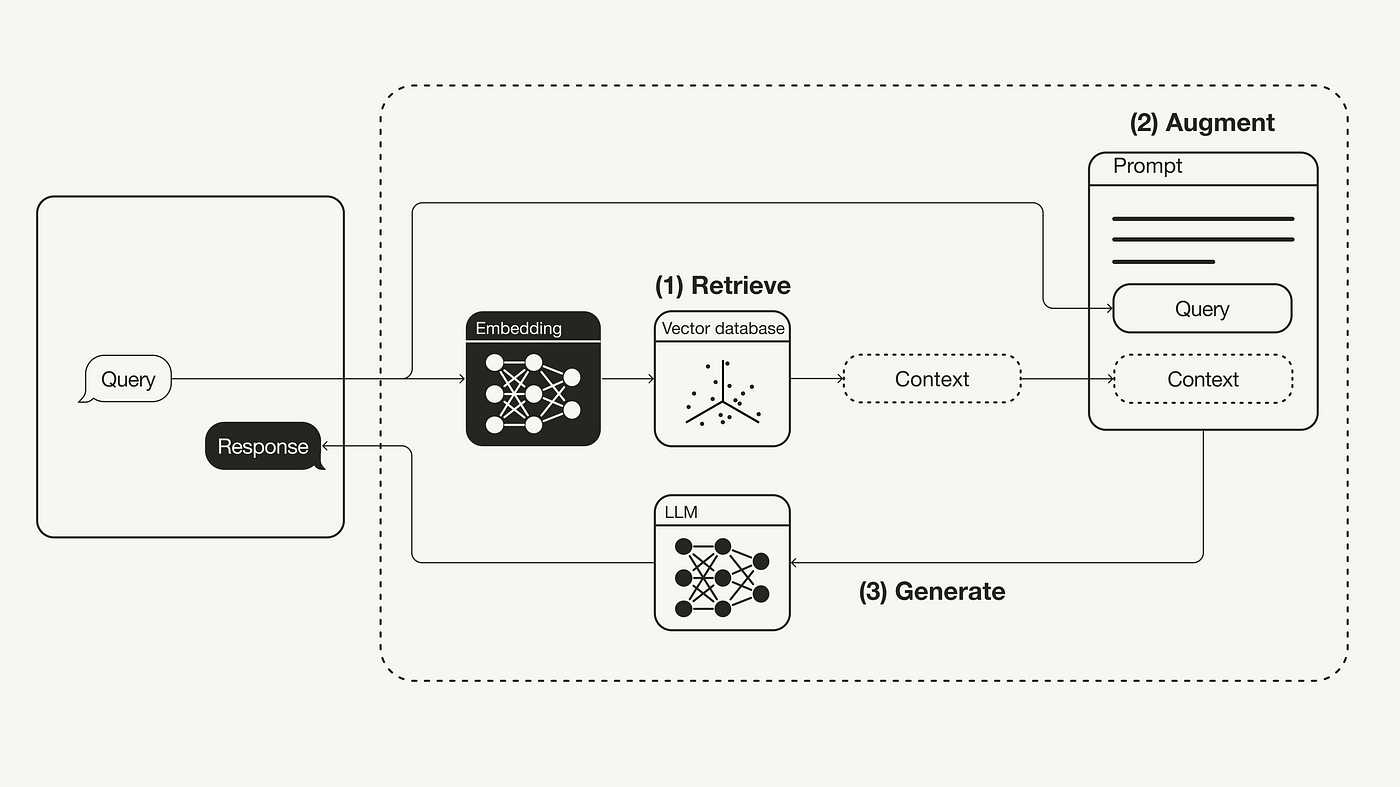
Observe que, como eu disse, RAG é um processo. Não temos, necessariamente, um ícone que simbolize uma aplicação RAG ou coisa semelhante. O que nós temos é um processo incluso no processo de geração de resposta pelo LLM.
Na imagem acima, temos a entrada do usuário (query) percorrendo um processo que antecede, propriamente dito, a geração de resposta pelo modelo de linguagem. Agora, o que esse processo anterior é? É, em resumo, o RAG.
Mas, de forma que consigamos simplificar um pouco mais nosso diagrama e a explicação sobre isso tudo, imagine que RAG, hoje, como aplicação de software, se concentra muito nesse fluxo abaixo:
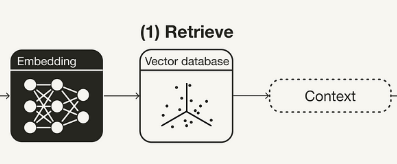
Ou seja, grande parte dos processos que envolvem geração de respostas por um modelo têm, antes do modelo em si, uma aplicação que (1) pega a pergunta do usuário e cria um vetor numérico dela e, depois, (2) faz uma busca vetorial em uma base de dados para, então, (3) gerar a resposta que eu mandarei para o meu modelo, inputando-a dentro de um prompt. Mas, fora essa simplificação toda, a RAG é o processo como um todo, e isso compreende: (1) pegar o input feito e utilizá-lo na busca de uma resposta mais semelhante na base de dados; (2) a geração de um prompt específico contendo a pergunta do usuário e a resposta mais semelhante (ou as mais semelhantes) da base; e (3) a passagem desse prompt para o modelo de forma que ele consiga inferir corretamente sobre a pergunta do usuário.
Próximos passos
Uma das coisas que me deixa muito reflexivo atualmente sobre RAG é como fazê-la ou como fazê-la da melhor forma. É certo que cada jeito ou forma deve se adequar a um caso específico. Por exemplo, eu posso querer construir uma aplicação RAG que tenha uma base de dados sobre alterações em um site e imagine que a aplicação que necessita dessa RAG requer muito poderio no quesito busca semântica. Então, a aplicação não pode me retornar coisas diferentes para uma mesma entrada ou para entradas que tenham palavras sinônimas dentro da sentença (ex.: “quero mudar meu endereço de e-mail”, “quero trocar meu endereço de e-mail”, “quero alterar meu endereço de e-mail”). Como fazer isso? E se ela retornar uma resposta para cada pergunta, como corrigir?
A ideia, nos próximos artigos, é conversarmos um pouco mais sobre isso. Também estou aprendendo e gostaria de compartilhar isso tudo com vocês.
Até a próxima. <3